Lektion 08
Pandas — DataFrames in der Praxis
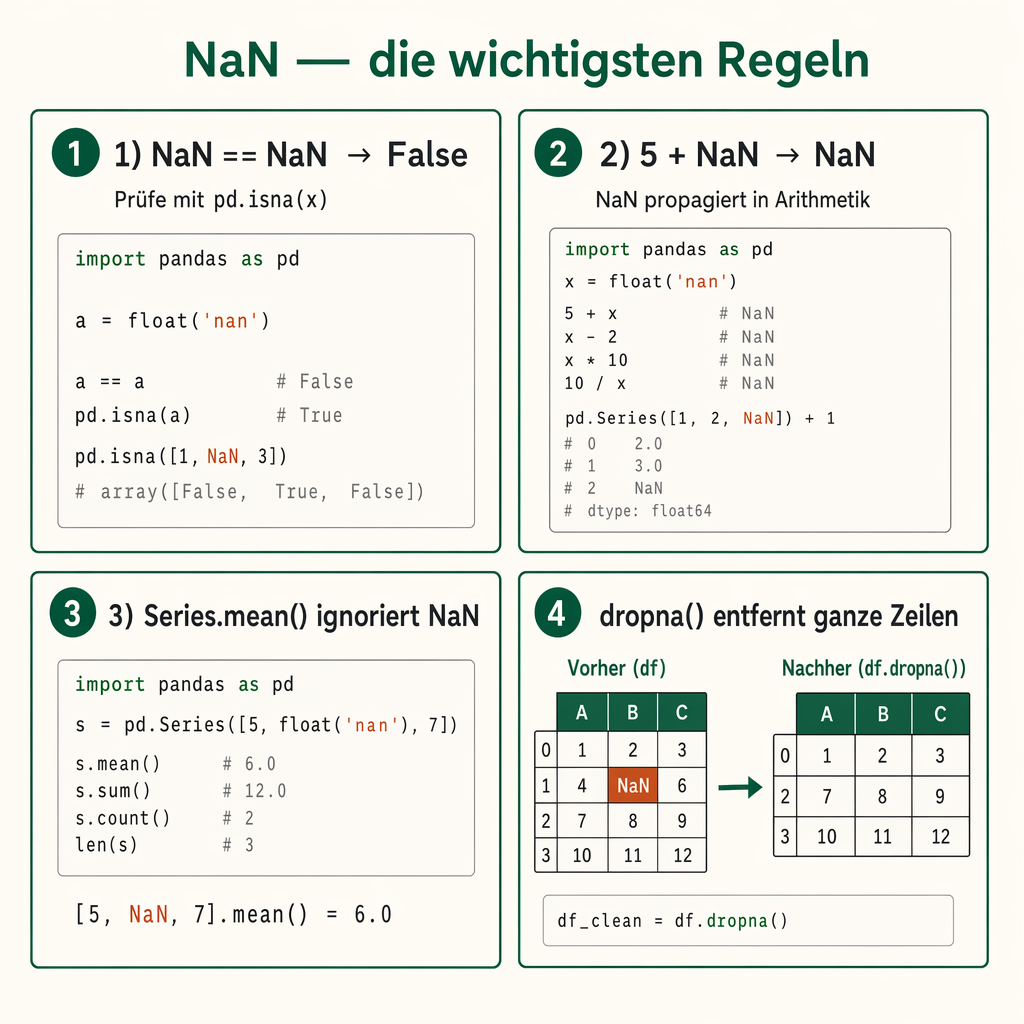
Lade CSV-Daten in einen DataFrame, navigiere mit loc/iloc, behandle NaN sauber, gruppiere mit groupby und sortiere — die fünf Operationen, die in Quiz 08 immer wieder geprüft werden.
- Dauer:
- 60 Min. geschätzt
- Voraussetzungen:
- Funktionen (Lektion 03) · Listen und Dictionaries (Lektion 05)

![Cheat-Sheet: loc vs. iloc. Tabelle mit Index-Labels 25, 7, 12, 4 und iloc-Positionen 0–3 daneben. Beispiele: df.loc[2] → KeyError, df.iloc[2] → AT.](/img/lessons/cheat-loc-vs-iloc.png)
![Cheat-Sheet zu groupby: Drei Phasen split, apply mean(), combine mit konkreten Werten und der zugehörigen Codezeile df.groupby('gruppe')['wert'].mean().](/img/lessons/cheat-groupby.png)